Linux小记¶
Linux本身是一个庞大的话题,关于Linux也有不少优秀书籍,想完全罗列其功能细节是不现实的,也没有这个必要!本文从实际应用的角度归纳多个方面的一些细节,同时做一些试验以佐证和回答一些问题。(有些内容可能与Linux应用无关,但比较有意思,也在此讨论)
浅析动态库¶
关于函数库,大家都知道有静态库和动态库两种,这里将从另外一些角度来探讨共享库,首先以下列表给出了所有种类:
| 目标平台 | 静态库 | 动态链接库 | 动态加载库 |
|---|---|---|---|
| MacOSX | .a/.framework | .dylib/.framework | .so/.bundle |
| Linux | .a | .so | .so |
| Windows | .lib | .dll(Native) | .dll(Native) |
| 编译参数 | ar -rc xxx.a xxx.o | gcc -shared -fPIC |
在上表中,Windows一栏的dll后缀标注了Native字样,用于说明该dll是由C/C++等语言编译出来的平台相关库,而不是C#之类的语言编译出来的IL字节码库。
Mono或者VS编译C#得到的是通用IL格式的库,其后缀也是dll,通过file命令检查这两种类型的dll你就会发现它们是不一样的;C#编译出来的dll,可以通过dnspy之类的反编译工具得到类似原始的C#代码,而通过C/C++编译出来的dll,是无法反编译的,你只能拿到汇编指令代码!
.a库或.lib库比较简单,就是普通C/C++代码编译产物.o文件的打包集合,没什么特殊,不同平台上都类似。即使是MacOSX上的静态framework,也只是.a库加上其他资源(如头文件)的集合。
由上表可知,虽然我们一般只说静态库和动态库,但是其实动态库中还分为两种,我称之为动态链接库和动态加载库,其区别如下:
- 动态链接库在exe执行main函数之前就全部由动态链接器加载到内存中(即使函数地址的解析是延迟的)
- 动态加载库对应于dlopen系列API,是在main函数开始执行之后,由工程师自己控制何时加载,包括函数地址解析等(dlsym函数)
- Linux中,通过dlopen系列API加载的库,与动态链接库一样不占用文件描述符
在Linux平台上,动态链接库和动态加载库毫无区别,两者是完全一样的,我们可以将它们用于gcc编译ELF文件时的动态链接,也可以用dlopen系列API动态加载它们。
在MacOSX平台上则体现出两者的区别:
- .dylib文件即为 Dynamic Link Library,用于动态链接
- .framework文件一般是动态链接库文件+相关头文件的组合,因此可视为与.dylib是同一种东西(可以存在静态framework)
- .dylib文件既可以通过-lxxx的方式参与gcc/clang命令编译,也可以通过dlopen系列API来动态加载
- .so文件原意为SharedObject,共享对象
- .bundle文件则是资源的集合,包括图片、音乐等,也可以存放.so文件(此时将.so文件当成一种资源,从这个角度看,MacOSX上.so文件与.bundle文件可视为同一种东西)
- .so/.bundle文件只能通过类似dlopen系列API来动态加载,无法通过-lxxx参数参与gcc/clang编译命令
在Mac下,gcc命令(clang的马甲)通过指定-dynamiclib参数可以编译出dylib动态链接库(默认会有-fPIC参数,无需显式指定),通过-bundle参数可以编译出bundle动态加载库。
关于MacOSX中dlopen相关历史:(参考此链接)
- MacOSX10.0中,不支持动态加载库
- MacOSX10.1中,引入一组dyld系列API,支持动态加载和卸载bundle,不支持动态加载dylib
- MacOSX10.3中,添加了dlopen系列API,依然不支持动态加载dylib
- MacOSX10.4中,重写了dlopen的实现,支持动态加载dylib,不支持卸载dylib
- MacOSX10.5中,支持动态卸载dylib,并弃用dyld系列API
简单归纳一下上述内容:
- MacOSX:两种动态库,.dylib文件同时支持编译链接和dlopen,.so文件仅支持dlopen,不支持编译链接
- Linux:仅一种动态库,.so文件,同时支持编译链接和dlopen
- Windows:两种dll,Native的dll同时支持编译链接和dlopen,.Net平台的dll需要CLR来加载和解释(通过Mono,.Net平台的dll是可以跨平台运行的)
我写了一个测试工程放到了Github上,分别编译出三个平台的多种库文件,以下是用相关命令查看的相关输出:
# MacOSX 静态库
$ file libhello_a.a
libhello_a.a: current ar archive random library
$ otool -hv libhello_a.a
Archive : libhello_a.a
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
MH_MAGIC_64 X86_64 ALL 0x00 OBJECT 4 1400 SUBSECTIONS_VIA_SYMBOLS
# MacOSX 动态库
$ otool -hv libhello.so
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
MH_MAGIC_64 X86_64 ALL 0x00 BUNDLE 12 1088 NOUNDEFS DYLDLINK TWOLEVEL
$ otool -hv hello.bundle/Contents/MacOS/hello
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
MH_MAGIC_64 X86_64 ALL 0x00 BUNDLE 12 1088 NOUNDEFS DYLDLINK TWOLEVEL
$ otool -hv libhello.1.0.dylib
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
MH_MAGIC_64 X86_64 ALL 0x00 DYLIB 13 1144 NOUNDEFS DYLDLINK TWOLEVEL NO_REEXPORTED_DYLIBS
$ otool -hv hello.framework/hello
Mach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
MH_MAGIC_64 X86_64 ALL 0x00 DYLIB 13 1152 NOUNDEFS DYLDLINK TWOLEVEL NO_REEXPORTED_DYLIBS
# Linux 静态库
$ file libhello_a.a
libhello_a.a: current ar archive
# Linux 动态库
$ file libhello.so.1.0
libhello.so.1.0: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=b0dc9c08769ea18405d0847c63df1e57f4cc0a67, not stripped
# Windows 静态库
$ file hello_a.lib
hello_a.lib: current ar archive
# Windows 动态库
$ file hello.dll
Debug/hello.dll: PE32+ executable (DLL) (console) x86-64, for MS Windows
# C# dll
$ file lib/Debug/hello.dll
lib/Debug/hello.dll: PE32 executable (DLL) (console) Intel 80386 Mono/.Net assembly, for MS Windows
其实在CMake的指令配置中,add_library指令就提供了STATIC、SHARED、MODULE三种类型可供选择,这三种类型就是对应静态库、动态链接库、动态加载库!
动态库加载方式¶
我们常说软件被启动的时候由系统加载到内存中,某动态库被自动加载到内存中,在此我先提出三个问题:
- 这个“加载”具体指的是什么?
- 加载过程是否由操作系统完整的将整个动态库二进制读到物理内存中去?
- 动态库为什么能够在多个进程之间共享代码段?
说到这些问题,不得不考虑mmap系统调用:
void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
其中,addr代表起始地址,len代表内存映射长度,prot和flag分别表示保护标志和映射标志,fd表示对应文件描述符,offset表示文件内偏移。
在mmap系统调用中,有一个我们很熟悉的参数:文件描述符fd,我们可以通过mmap系统调用,将fd文件描述符指定的文件映射到系统内存中,这里的映射包括两层:
- 文件块映射到物理内存页
- 物理内存页映射到进程虚拟内存页
注意,mmap执行的映射过程,并没有将对应文件读入内存,仅仅是将内存虚拟地址空间保留给该文件,当用户通过read/write之类的方式操作对应虚拟内存地址时,内核再实际分配物理内存用于缓冲和数据交换,因此,对于巨大文件(比如2G甚至更大的文件),mmap系统调用也可以迅速返回。
加载动态库也只是通过类似mmap的方式做好内存与库文件的映射,对于Linux来说:
- 动态链接库和动态加载库实现库文件内存镜像供多个进程共享的根本点在于mmap系统调用
- 系统内核加载可执行文件只读数据段和代码段原理也类似mmap系统调用
因此,同一个可执行文件的多个运行进程,都共用同一物理内存的可执行代码段和只读数据段。(ELF格式文件其实有两种分段的说法,第一种分段是针对二进制文件本身,如BSS、DATA、TEXT,第二种分段则是对第一种分段进行分类,分为读写部分和只读部分,只读部分可以用于共享,包括代码段、只读数据段)
简单归纳如下:
- 加载exe或者加载so都是通过mmap进行,1M的exe和1G的exe启动速度基本一样(这里的1M和1G指的是单独一个可执行文件的大小,动态库的大小也基本不影响加载时间)
- 多个进程或者多个线程dlopen同一个共享库(必须是同一份磁盘文件),这些进程或者线程都共用同一份物理内存中的共享库代码段
- 同一个动态链接库被多个可执行文件动态链接,那么这些可执行文件同时运行起来的时候,共用物理内存中该动态链接库的代码段和只读数据段
- 同一个exe开启的多个进程,共用物理内存中该exe的代码段和只读数据段
到这里,我们可以回答上述提出的问题:
- “加载”具体指的是做好动态库文件与虚拟内存地址区间的映射关系
- 加载过程不读取共享库的二进制数据,加载结束的时候只保证该二进制共享库在该进程有一段分配好的虚拟地址区间。等到进程执行到相关位置,需要用的时候,才由系统底层缺页中断实际从磁盘读取相关内容到物理内存中(该物理内存映射到对应虚拟内存地址区间)
- mmap系统调用将不同进程的虚拟地址区间映射到了同一份物理内存地址,因此可实现动态库共享,这种共享方式类似不同进程之间的内存共享(进程视角只能看到虚拟内存,内核视角则管理着不同进程与实际物理内存的映射关系)
By the way,类似mmap系统调用,我们常用的malloc函数(或其他语言的new操作符)分配的内存也是虚拟内存空间,只有当进程实际对该空间进行读写(如memset),内核才会真正为其分配物理内存页(以页为单位)。
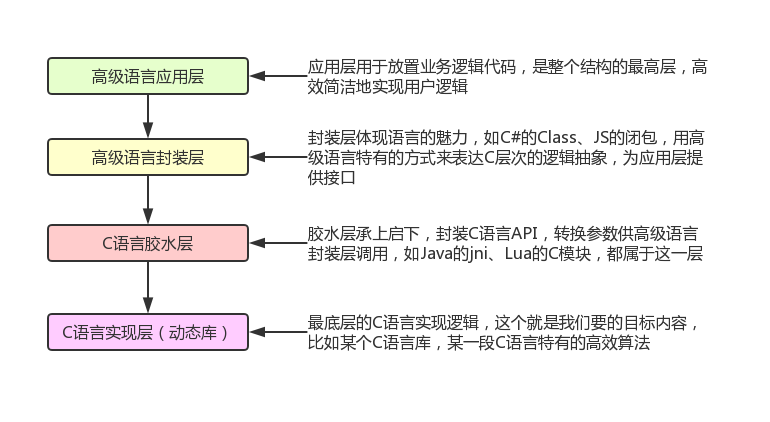
语言间通信¶
动态库拥有诸如代码共享、节省内存之类的优点,经常被用于程序代码模块化或插件化的具体实现方式;动态库本身就是一个可配置的结构,比如多个动态库形成的单向引用链;另外,动态库也是高级编程语言与C语言通信的重要方式。
动态VM脚本语言与C/C++交互的方式主要有三种:
- 编写C/C++代码,并将其编译进脚本VM,成为VM的一部分
- 将C/C++代码按照某种格式编译成动态库,由脚本语言通过VM底层支持来动态链接或者运行时加载
- 将脚本语言VM整个嵌入到C/C++宿主环境,C/C++通过VM提供的CAPI与脚本语言交互
简单说明如下:
- 第一种方式需要定制脚本语言的解释器,除非有特殊用途,我们一般不会采用这种方式(为了通用)
- 第二种方式也就是应用动态库,这种应用很广泛,比如PHP后台加载扩展模块、UnityC#应用加载Native动态库,都是采用这种方式
- 第三种方式的典型应用是嵌入式脚本语言(如Lua/MonoC#)。将脚本语言的VM嵌入C/C++宿主环境,是一种优秀的应用结构,基础操作由C/C++高效提供,脚本语言在高层次实现高效开发,既满足了运行效率,又提高了开发效率,目前大多数软件设计会采用类似的结构
主流编程语言都支持第二种方式,具体实现细节因语言而异,想了解具体内容的同学可以从我的Github上获得主流7种高级语言通过动态库调用C函数的用法Demo,包括C#、Go、Java、Lua、NodeJS、PHP和Python!
高级语言调用C语言的逻辑结构:
库函数符号引用¶
我们知道,对于静态库,打包过程中对于没有用到的.o文件默认不会打进exe或者动态库中,然而,有时候我们想通过运行时dlsym的方式来获取函数地址并调用,此时,即使没有被显示调用到的函数,也应该将.o文件打进最终二进制文件中,那么我们该如何控制这步操作?(Linux下需要-rdynamic编译参数将exe本身所有符号加入动态查找符号表中,dlopen(NULL)得到的句柄是exe本身的)
其实gcc已经提供了这种功能的支持,具体使用方式是通过编译参数来控制,这里列出gcc/Objective-C/Android三种环境下的编译参数和配置:
- gcc编译命令中添加链接参数:-Wl,--whole-archive -Wl,--no-whole-archive
- 针对Objective-C,苹果提供了-ObjC编译参数
- Android的ndk-build相关mk配置文件中,提供了变量来设置对应静态库:LOCAL_WHOLE_STATIC_LIBRARIES和LOCAL_STATIC_LIBRARIES
动态库查找¶
关于头文件或库的查找顺序:
-
gcc编译过程查找尖括号头文件顺序:
-
-I指定的路径(这里是i的大写,不是L的小写)
- 环境变量CPATH等
-
/usr/include+/usr/local/include+gcc库头文件
-
gcc编译过程查找库文件顺序:
-
-L指定的路径
- 环境变量LIBRARY_PATH
- gcc --print-search-dir | grep libraries
-
ld -verbose | grep SEARCH_DIR
-
运行时查找动态库顺序:
-
DT_RPATH(无DT_RUNPATH时)
- 环境变量LD_RUN_PATH(无DT_RUNPATH且无DT_RPATH时)
- 环境变量LD_LIBRARY_PATH
- DT_RUNPATH
- /etc/ld.so.conf+/lib+/usr/lib
gcc编译参数-Wl,-rpath指定的路径将作为可执行文件的DT_RPATH值
gcc编译参数-Wl,-rpath指定路径并且有参数-Wl,--enable-new-dtags则将该路径作为可执行文件的DT_RUNPATH值
gcc命令传递参数给各个编译阶段:
- -Wa,\<options> Pass comma-separated \<options> on to the assembler
- -Wp,\<options> Pass comma-separated \<options> on to the preprocessor
- -Wl,\<options> Pass comma-separated \<options> on to the linker
动态库小结¶
从一个整体的角度来考虑,用户态编程与系统内核层次可简单归纳如下:
- 三个层次:1.应用程序 2.系统库/私有库 3.系统内核
- 两个接口:1.应用程序与系统库/私有库之间的接口 2.操作系统提供的接口(系统调用)
作为一个软件工程师,我们不仅要了解系统库/第三方库提供的接口API,更要熟悉操作系统为我们提供了哪些基础操作;调用某一个函数或者执行某一条命令时,我们要能够明确的分析出哪些功能是在内核态实现哪些功能是在用户态完成。不谋全局者,不足以谋一域;不谋万世者,不足以谋一时。
关于Linux动态库的更多细节,请参考《Linux/Unix系统编程手册》一书第41、42章,以及《程序员的自我修养:链接、装载和库》一书
Shell命令与IO¶
我们在交互式Shell输入命令完成任务或者编写Shell脚本,都是围绕IO来进行操作的。操作命令的思维模式中,主要包括三个部分:
- 该命令本身的名称
- 该命令支持哪些参数
- 该命令如何实现IO
其中,命令如何实现IO是比较重要的一个环节,我们必须熟悉这一层才能够高效的操作Shell,因此这里做一个简单的归纳。
Shell命令IO交互图:
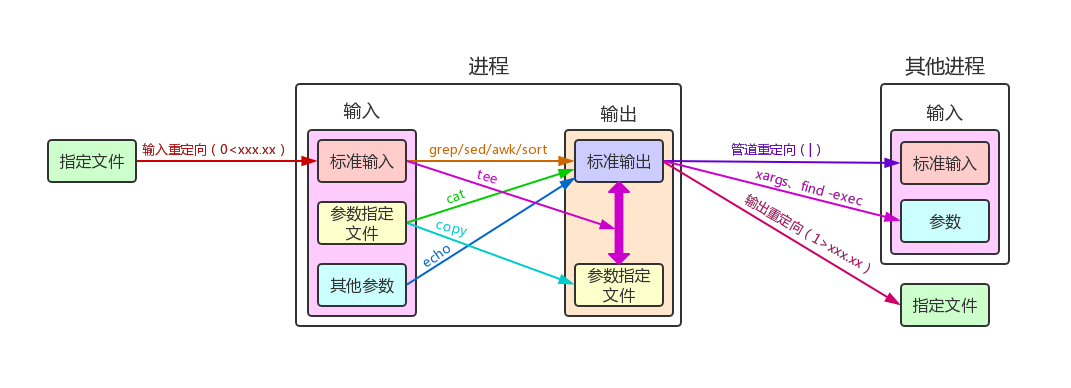
Shell操作中的数据流向
- 输入参数==>标准输出:直接将命令参数内容打印到标准输出,如echo
- 参数指定的文件==>标准输出:命令参数指定文件路径,命令将文件内容做一定处理,并将结果打印到标准输出,如cat xxx、head -n 2 xxx、tail -n 3 xxx等
- 标准输出==>指定的文件:将进程标准输出连接到指定文件,这属于输出重定向,如在命令中指定1>xxx.txt
- 指定的文件==>标准输入:将进程标准输入连接到指定文件,这属于输入重定向,如0\<xxx.txt
- 前一个命令的标准输出==>后一个命令的标准输入:大家最熟悉的管道重定向,这也是最常见的shell操作
- 标准输入==>作为参数调用参数指定的新命令:将前面命令的结果作为后续命令的参数,用xargs之类的命令作为媒介(显然新命令跟xargs不是同一个时期启动的进程了,find命令的-exec参数可以实现类似功能)
- 标准输入==>标准输出+参数指定的文件:目前仅tee命令有用这种效果,当然我们可以自定义相关命令
一个标准进程的基本结构为:从命令行参数/标准输入/指定文件获取数据,处理数据,并将结果输出到标准输出/指定文件
Shell命令操作:
- 使用管道同时执行多条命令之后,echo ${PIPESTATUS[*]}可以打印出所有管道中的命令的退出状态码,echo ${#PIPESTATUS[@]}可以获得管道进程数量,read命令可以从标准输入读取数据
- 进程读取写端已经关闭的管道或Socket(缓冲区已空)会得到EOF(就是read系统调用返回0),写入读端已经关闭的管道或Socket,会触发SIGPIPE信号
- 系统不允许管道或者Socket只有一端被打开,因此,当只有一个进程以读或写的方式打开管道/Socket,其会阻塞在open系统调用上(这里不考虑非阻塞文件描述符,并且,这里的管道指的是命名管道,通过mkfifo创建)
- cmd1 | cmd2 | cmd3这样的管道执行命令中,三个命令是同时创建进程并同时运行的,假如cmd2命令早于cmd1退出,会造成cmd1写入标准输出的时候触发SIGPIPE,cmd3早于cmd2退出也会有类似的结果,具体可查看我Github的验证示例
- echo “Hello” | tee tmp.txt | grep He 0\< tmp2.txt 这条命令中,tee命令进程会收到SIGPIPE,因为grep的标准输入被重定向到tmp2文件之后,原本的管道被关闭,tee往标准输出写入数据就会触发SIGPIPE
- 用户在退出终端并关闭会话的时候,会话首进程(也就是bash)会收到SIGHUP信号,这个信号会导致bash退出,并且在退出之前,交互式bash会给所有任务进程发送SIGHUP信号(同一个会话组),因此,为了让进程在用户退出终端之后继续运行,有三种方式,一是让新启动的进程忽略SIGHUP信号,二是让新启动的进程运行于一个新的会话中,三是构造一个非交互式Shell的环境,更多细节请参考这篇博客
我们所说的管道包含两种:匿名管道和命名管道
- 匿名管道:通过pipe函数创建(功能类似的有 socketpair 函数创建的UnixSocket对)
- 命名管道:通过mkfifo函数创建(功能类似的有 STREAM 类型的 UnixSocket)
- UnixSocket作为一种类似管道功能的进程间通信方式,同时支持字节流的类型和数据报的类型
常见命令的典型用法:
# -n参数指定一次执行个数,-t打印命令,-I指定替换字符串
echo "a b c" | xargs -n 1 -t -I \{\} grep "tmp" \{\} -v
seq 24929 24939 | xargs -n 1 -I \{\} rm xw_\{\}_0_product.apk
# find命令打印出以空终止的字符串集合
find . -name "*.c" -print0 | xargs -0 -n 1 -t gcc -std=c11
# 字符串替换
echo "hello world" | sed "s#wor#WOR#"
# 统计文件夹中所有源码总代码函数
find . -type f -exec wc -l \{\} \; | awk 'BEGIN{ALL=0}{ALL+=$1}END{print ALL}'
# find命令实现类似tree命令的功能
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
# 只打印前几行或后几行
cat xxx.txt | head -n 4
cat xxx.txt | tail -n 5
# 打印所有Shell变量
declare -p
# declare命令 -a表示索引数组(普通数组),-A表示关联数组(键值对),-x类似export命令
# 在后台运行进程(登陆终端之后可以用这些方式让进程在用户退出终端之后继续运行于后台)
nohup cmd args 1>log.txt &
# nohup忽略SIGHUP信号,并且有如下操作
# 标准输入是终端,则将其重定向到/dev/null,通过unistd.h中的函数isatty(fd)来判断
# 标准输出是终端,则默认重定向到CWD的nohup.out
# 标准错误是终端,则默认重定向到标准输出
# nohup启动的进程依然是bash的子进程
# 在新会话中运行进程,setsid启动的进程是init的子进程
setsid cmd args 1>log.txt &
# 在子终端中执行带&的命令
(ping www.baidu.com &)
# 子终端不是交互终端,结束的时候不会给job发送SIGHUP,因此后台进程得以继续运行
# 如何进程已经启动
disown -h jobspec # 使某个任务忽略SIGHUP信号
# 将"\uXXXX"之类的ASCII转义字符转换成Unicode编码
native2ascii -reverse -encoding UTF-8 xxx.txt
# 将文件的GBK编码转换成UTF-8编码
iconv -f gbk -t UTF-8 xxx.txt > yyy.txt
# 换行符切换命令
unix2dos xxx.txt
dos2unix xxx.txt
# xxd命令以16进制的格式查看二进制文件
# Linux下grep添加-P参数以开启perl类型的正则匹配,支持前向预查等
grep -P -o "(?<=XX)YY(?!ZZ)" xxx.txt
# zsh撤销上一步操作用的是Ctrl+Shift+_,对于使用Tab补足的异常情况很有用
# brew 使用代理来下载命令工具
ALL_PROXY=socks5://127.0.0.1:1086 brew install watch
# Xcode重新安装CommandLineTools
sudo rm -rf /Library/Developer/CommandLineTools
xcode-select --install
# Windows下使用git的配置:
git config --global core.autocrlf true
git config --global core.safecrlf true
git config --global core.filemode false
文件系统操作¶
所有的文件系统操作:
| C库封装 | 系统调用 | 描述 |
|---|---|---|
| fopen | open | 打开文件 |
| fclose | close | 关闭文件 |
| fread | read | 读文件 |
| fwrite | write | 写文件 |
| ftruncate | 截断或扩展文件内容长度 | |
| link | 创建硬链接 | |
| symlink | 创建符号链接,就是软链接了 | |
| readlink | 读取软连接内容 | |
| rename | 文件重命名 | |
| unlink | 断开文件链接,其实就是删除文件夹表项 | |
| mkdir | 创建文件夹 | |
| rmdir | 删除文件夹 | |
| access | 检查文件权限 | |
| chmod/fchmod | 修改文件权限 | |
| chown/fchown/lchown | 修改文件属主 | |
| stat/fstat/lstat | 获取文件状态信息 | |
| statfs/fstatfs | 文件系统状态信息 | |
| utime/utimes/futimes/lutimes | 修改文件时间戳 | |
| fsync/fdatasync | 同步内核文件缓冲区到磁盘 | |
| sendfile | 内核态两个文件描述符复制内容 | |
| mkdtemp | 临时文件夹 | |
| opendir | 打开文件夹 | |
| closedir | 关闭文件夹 | |
| readdir | 读取文件夹内容 | |
| scandir | 扫描文件夹 | |
| realpath | 文件真实绝对路径,解出符号链接引用和/../ |
文件操作与底层inode关系图:
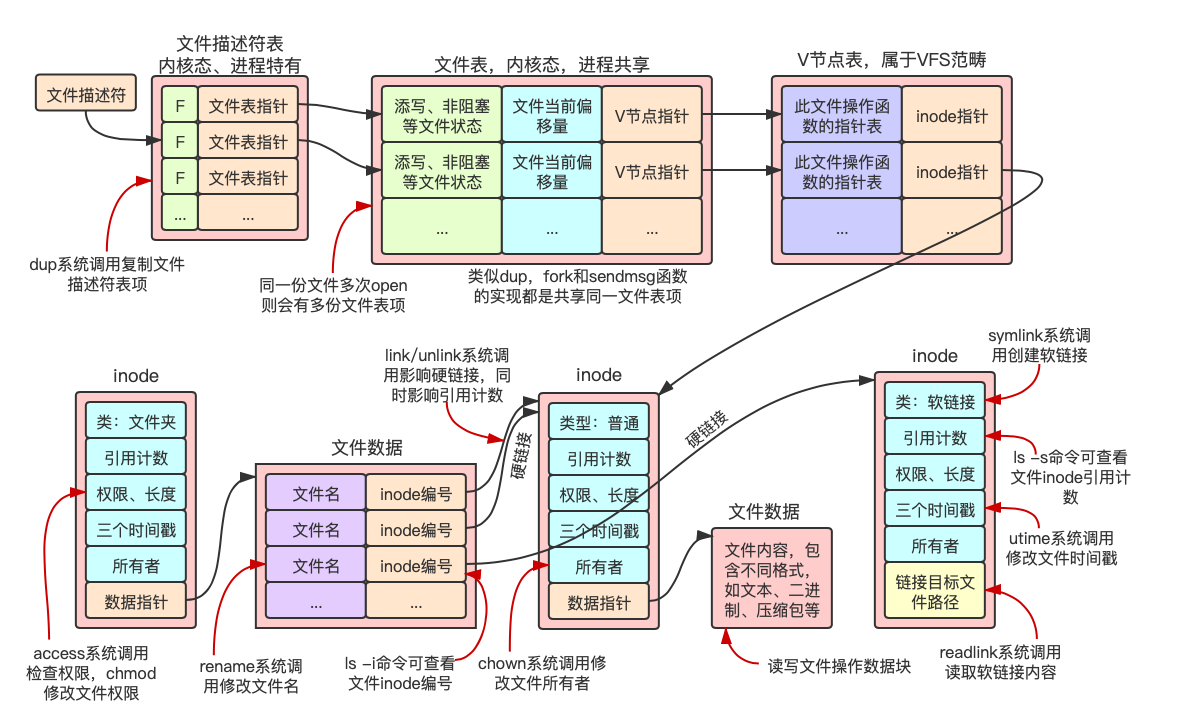
如上图所示,这里给出几点说明:
- 图中文件描述符表项的F表示close-on-exec的描述符标志,代表着execve的过程是否关闭该文件描述符
- 磁盘中一个文件包括两部分,一是inode中的元数据(元数据包括文件类型,所有者ID,权限等)二是数据块(inode中数据指针指向数据块)
- 目录是一种特殊的文件,其数据块存放的是文件名与文件inode节点号的对应关系
- 软链接是一种文件类型,术语称之为符号链接
- 硬连接只是一个术语,表示inode引用计数,并不是文件类型,多个文件名可以指向同一个inode,关于硬链接的更多细节,可以参考这篇博客
- rm或unlink命令仅作用于文件夹中文件记录项,并且会影响inode的硬链接引用计数,只有当引用计数为0的时候,才会真正删除该inode的对应的文件数据块。
- 符号链接文件用inode中的数据指针位置直接存放目标文件路径是一种优化(原先是将目标文件路径放在数据指针指向的数据块中)
- dup系统调用复制的文件描述符共享文件偏移值,因此,对这两个文件描述符进行write不会相互覆盖(前一个write完会更新偏移值)
- 同一个进程多次open同一个文件或者多个进程open同一个文件,会存在多份内核文件表项,此时对该文件的多次write会出现互相覆盖的情况(多次open肯定有多个文件描述符了)
关于文件属性的时间戳:
- atime(access,ls -u命令可显示这个时间):文件内容上次被访问的时间
- mtime(modify,ls默认显示这个时间):文件内容上次被修改的时间
- ctime(ls -c显示这个时间):文件i节点内的信息上次发生改变的时间
- Linux下的 stat file.txt 命令(MacOSX下是 stat -x file.txt)可显示文件状态的详细信息,包括这三个时间戳
- 文件i节点被访问的时间并没有记录,Linux的文件系统也没有记录文件的创建时间
- MacOSX和Windows下的文件系统有记录文件的创建时间,在桌面系统下可以轻松查看
在此,我提出一个问题:当我们在进程运行过程,删掉该进程的二进制文件,会触发什么情况?
仔细思考便可得出,通过rm命令删掉二进制文件的时候,只是删掉了对应文件夹表项,并不会真的删掉文件数据块(因为有V节点引用着inode),进程仍然能够继续运行,等到进程结束或关闭该文件描述符的时候,发现inode引用计数为0,此时该inode和文件数据块就会被真正释放。(这种操作正是Linux系统创建临时文件的做法,先用一个随机复杂名称创建一个文件,而后open该文件并unlink它,此时该文件对应的inode及数据块就只有该进程能访问到,等到进程结束或者显示close该文件的时候,该文件即被真正删除)
关于阻塞与异步,这是我的理解:
- 阻塞和非阻塞说的是当前执行流是否被IO卡住,能否在IO执行的过程继续执行当前执行流
- 异步和同步说的是当前执行流与IO执行流是否有同步交互,比如,当前执行流循环去查询IO执行流的状态,那说明是同步的,如果当前执行流靠IO执行流通过信号或eventfd等方式来通知IO执行流的状态,那这个过程的时机是不确定的,所以这两者是异步的
- 按照我的理解,在同一条线程内,阻塞一定同步,异步一定非阻塞
更多信息请参考以下资料:
- 《Linux/Unix系统编程手册》一书第4、5、18章
- 《Unix环境高级编程》一书第3、4章
- 《深入理解计算机系统》一书第10章
C语言小结¶
C语言函数指针推荐用法:
#include <stdio.h>
typedef int (*FunctionDefinition)(int x);
int mul2(int x) {
return x*2;
}
FunctionDefinition func;
func = mul2;
int y = (*func)(12); // int y = func(12);
在第一小段C语言代码中,FunctionDefinition被定义为一个函数指针类型,指向一个函数,func变量被定义为一个函数指针,而函数名代表该函数首地址,因此,将函数首地址赋值给函数指针合情合理,调用该指针所指向的函数时,加上*以表明该变量是一个指针(清晰明确的将该变量当成普通指针使用),考虑到指针中放的是函数地址,直接对其调用也是符合函数名代表函数首地址的含义。
当然,可以将FunctionDefinition定义为函数原型,而不是函数指针,此时,func变量的定义应当加上*以表示func是一个指针,用法一样。
问题:如何简单构造一个100M大小的二进制文件?
其实只要你有足够的代码量,是可以编译出100M大小的二进制文件,然而这个问题的目的并不是让你找出这么多代码,而是抛砖引玉引出另一个问题:普通C/C++代码中,哪些写法会导致二进制大小巨增?写出来你可能不信,如下简单的HelloWorld程序,编译结果居然二进制大于100M:
#include <stdio.h>
char buffer[100*1024*1024] = "Hello World!";
int main(int argc, char* argv[]){
printf("%s\n", buffer);
return 0;
}
已经初始化的数组存放在二进制文件的可读写数据段,因而不管初始化字符串的长度,在二进制文件中都需要定义好的空间大小。假如将代码中的buffer定义为一个char型指针,或者运行时再去初始化buffer,则不会出现100M大小的二进制:
- 将buffer换成char型指针,则是改了其含义,赋值操作变成了将“Hello World!”字符串的首地址给buffer。
- 运行时再初始化的话,含义没变,但是buffer由于未初始化,其会被编译进二进制文件的BSS段,仅保留了数组大小的数值,没有占用实际空间。
说到这里,按照这个格式,我们可以构造任意大小的二进制文件!
近期研究了云风开源的pbc实现,发现云风很喜欢使用结构体数组类型,而非定义结构体+对应指针类型的方式:
typedef struct {
char* name;
int age;
} Person;
typedef struct {
char* name;
int age;
} PersonA[1]; // pbc中大量使用这种形式的定义
这里粗略对比两种定义的异同:
- 这两种方式定义的数据类型都可以直接用来定义某个变量,都会在栈上分配该结构体的内存空间
- 定义成结构体,访问其成员需要通过点操作来实现,想使用指针形式的操作需要再定义一个对应的指针变量
- 定义成数组,那么数组名就是首地址,不再需要通过取地址符号去获取地址了,操作也是直接指针形式的操作
- 函数参数类型为Person,则是值传递,需要传指针必须手动定义参数类型为Person*
- 函数参数类型为PersonA,则直接是传递的指针
- PersonA的写法很容易通过手动分配更多内存的方式,将其扩展为具备多个元素的数组,而不仅仅是一个结构体
相关测试代码可以看这里。
杂记:
- #pragma xxx预编译指令是不可移植的,编译器可以选择忽略不认识的#pragma指定指令,相关gcc编译参数为:-Wunknown-pragmas、-Wno-unknown-pragmas
- 函数前提条件或者运行结果尽量用更多的assert进行判断,提高软件可靠性
- 使用C语言标准IO注意事项:a. 输出文件是否以Append形式写入 b. 是否输出完冲刷IO缓冲 c. fread和fwrite不支持针对同一个文件描述符的连贯交叉混用(中间必须混合其他如fflush之类的操作)
- C语言开发之前遇到一个很隐蔽的问题,那就是数组下标允许为负数,当传入下标为负数的时候,会修改意想不到的内存地址,运气比较好的时候或许对该地址没有访问权限而直接收到系统信号,有时改的只是我们申请的另一块空间,完全合法,从而为后续访问埋下伏笔,当你某个时候访问了被修改的内存,然后就出现本来不可能出现的现象!!!或许这就是为什么大家都说C语言不安全的原因之一吧!
参考资料:《C专家编程》
内存属性¶
处于应用层高级语言开发的同学可能没有内存属性这个概念,其实操作系统管理的虚拟内存,系统层次上给予了它们一些属性,包括可读、可写、可执行,Linux中有这样一个系统调用:
int mprotect(void *addr, size_t len, int prot);
mprotect系统调用的作用是修改内存属性。比如:
- 可执行文件加载到内存中,代码段的内存页就设置为只读和可执行、不可写,只读数据段就设置为只读、不可写也不可执行
- 用作程序栈空间的内存设置为可读写不可执行(可以在一定程度上限制缓冲区溢出漏洞带来的危害)
内存属性来自于我们定义好使用某一个内存页的方式,当试图用不允许的方式使用该内存页时,系统触发异常而报错,很好理解,这是一种比较安全的做法。
随机访问¶
随机访问的含义是:CPU给出一个随机的地址,能否直接得到该地址上1个字节的数据。内存支持随机访问,只要地址总线上给出一个地址,CPU就能从数据总线上获得该内存地址上1个字节的数据。普通硬盘是不支持随机访问的,因为读写硬盘需要以块为单位,无法做到一次读取一个字节。
考虑51单片机的结构:51单片机包含RAM、ROM、运算单元等结构,RAM对应PC的内存,ROM对应PC的硬盘,运算单元对应PC的CPU。
不过,51单片机运行原理与PC有着天大的差别,那就是51的ROM支持随机访问,51的运算单元能直接从ROM中顺序读取一条条指令出来执行,无需将这一段需要运行的指令加载到RAM中,这也是为什么51仅有128字节的RAM也能满足基本需求。
普通PC无法做到这一点,就是因为硬盘不支持随机访问,CPU无法直接从硬盘读取指令,即使CPU知道它要的指令在硬盘的位置。CPU必须将指令块从硬盘读取到内存,然后再从内存读取一条条指令进行解码执行。
其他记录¶
- 二进制可执行文件引用私有动态库,此时将该私有库放于可执行文件某个相对路径下,假如rpath设置的是绝对路径,则可执行文件和库一块移动之后,无法正常运行,假如rpath设置为相对路径,则执行该可执行文件必须cd到可执行文件所在目录
- 典型小端模式:X86,典型大端模式:TCP/IP、PowerPC、51单片机。网络字节序是大端序,网络字节内部的比特序则是小端序
- Linux中针对X86_64的C语言函数调用参数传递方式为CPU寄存器:DI,SI,DX,CX,R8,R9(X86的是通过栈传递参数)
- atexit函数的底层实现为单向链表
- Linux允许进程给自己发送信号,但是在Linux中 kill(-1, sig) 并不会给调用进程发送信号
- 常见网络服务器负载均衡的三种方式:1. DNS 2. LVS 3. Nginx
- LVS的三种实现:1. NAT 2. IP隧道 3. MacAddress
- MD5等摘要算法只算文件内容,不包括inode的属性元数据和文件名
- 设计模式中常说的工厂方法指的是创建对象的函数,调用工厂方法能得到某个对象(表示该工厂生产了该对象)
- 大量分支结构可以采用的实现方式:switch+case、类的多态性、字典检索键值映射
- 进程主线程可调用pthread_exit函数先于其他线程结束运行,主线程结束后主线程的栈空间依然可用,且此时进程不会结束,直到所有线程都结束或者某个线程调用exit系统调用,具体可查看我的Github测试用例
- ASCII编码中,大写字母和小写字母的区别只有一个bit不一样,C语言中((c) | ('A' ^ 'a’))可将字符c转成小写