UE4基础设施¶
容器 Containers¶
除了常用的 TArray、TSet、TMap,UE 还提供了哪些容器可以开箱即用呢?
TArray 使用技巧¶
- 当知道需要往 TArray 增加的数量时,提前用
TArray.Reserve方法一次性分配空间。 - 当函数传参不需要复制整个 TArray 时,使用
const TArray<>&或TArrayView<>代替TArray<>。 - 当不关注 TArray 内元素的顺序时,删除一个元素可以用
TArray.RemoveAtSwap代替TArray.RemoveAt。 - 当删除元素时不希望 TArray 自动缩减内存时,多传递一个参数
bAllowShrinking给RemoveAtSwap, RemoveAll, RemoveAllSwap, RemoveSingle, RemoveSingleSwap来避免内存缩减。 - 使用自定义的内存分配器,如
TInlineAllocator,在定义 TArray 的地方直接给分配空间,而不是在堆上动态分配(这种方式定义的 TArray 变量不能用 UPROPERTY 标签)。 - TMap 和 TSet 中,Key 为 FName 时,必定忽略大小写。
TArrayView 与 TArrayBuilder¶
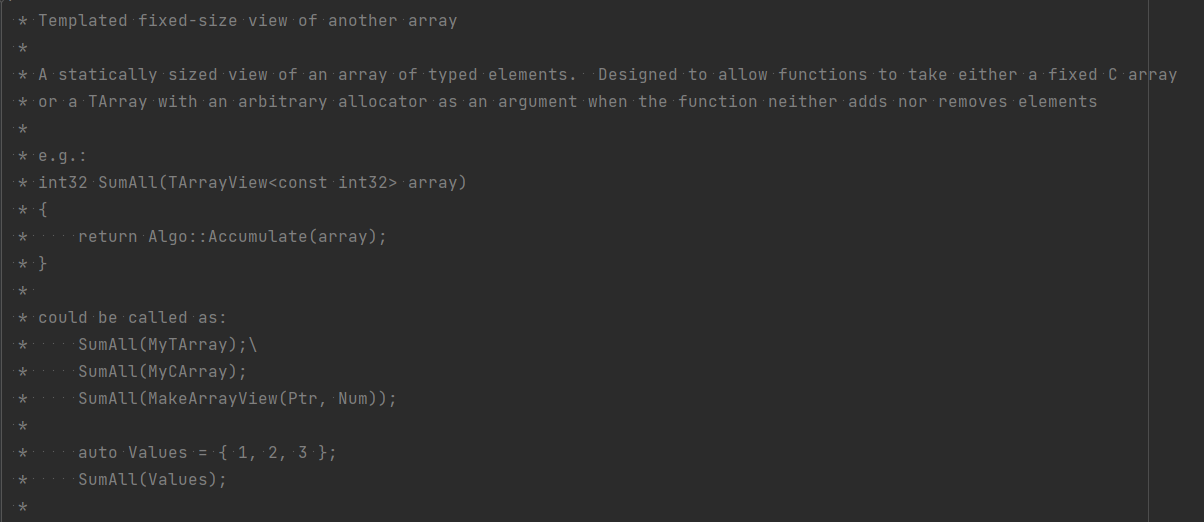
当函数参数是 const Tarray<>&时,可替换为 TArrayView:
void Process(const TArray<int32>& InList);
void Process(TArrayView<int32> InList);
当函数参数是 TArrayView 时,实参可以是:
- 部分 TArray
- C 原生数组
- std::initializer_list
TArrayBuilder 和 TMapBuilder 只是简化写法:
TArray<int32> List;
List.Add(43);
List.Add(55);
Process(List);
Process(TArrayBuilder<int32>().Add(43).Add(55).Build());
ProcessMap(TMapBuilder<int32, int32>().Add(43, 55).Build());
其他 Array¶
- TStaticArray: 给 C 数组包了一层,支持比较、拷贝、遍历等 TArray 用法。
- TBasicArray: 简化版的 TArray,无依赖(序列化、Algo 算法、内存分配器等)。
- TBitArray: bool 数组,一个字节放 8 个 bit,高效迭代所有为 true 的项。
- TStaticBitArray: 同上,固定大小版。
- TChunkedArray: 类似 TArray,底层分段存储数组,适合数组比较大的情况,避免大量 Realloc。
- TIndirectArray: 类似 TArray,所有对象都通过 new 创建,数组内只放指针,适合 F 类特别大的情况,不适合 UObject。
- TSparseArray: 稀疏数组,允许有洞,内存并没有比 TArray 少。
- TMRUArray: 类似 TArray,但最近添加的条目会被挪到最前
其他容器¶
- TQueue: 队列,线程安全,支持 单生产单消费 或 多生产单消费。
- TSortedMap: 自动排序的 TMap。
- TLinkedList: 非侵入式链表的一个节点,该节点直接包含元素对象。
- TIntrusiveLinkedList: 侵入式链表的一个节点,具体节点结构需要继承实现。
- TDoubleLinkedList: 双向链表。
- TLockFreePointerList: 无锁队列,具备 FIFO、LIFO、Unordered 等多个版本。
- TStaticHashTable: 哈希表,KeyValue 都是整数,一般用于索引其他数据结构,如配合 TArray 使用。
- FHashTable: 同上,可动态扩容。
- THashTable: 同上,支持自定义内存分配器。
- FBinaryHeap: 二叉堆,也称为优先级队列,最小的 Key 在堆顶。(比如可用于管理一系列定时器)。
- TCircularBuffer: 环形缓冲。
- TCircularQueue: 无锁环形队列,线程安全,仅支持 单生产单消费。
- TTripleBuffer: 三缓冲结构,包括 读、写、Temp 三个。
- TDiscardableKeyValueCache: 可丢弃的键值缓存,MRU 的条目被保留(MostRecentlyUsed),Discard 越频繁,保留时间越短。
- LruCache: 淘汰最近最少使用的条目(LeastRecentlyUsed)。
字符串 String¶
TCHAR 到底是个什么东西?
为什么字符串字面量要包一层 TEXT(“”)宏?
Unicode 编码¶
- “字符编码”是指 可打印“字符” 与 “存储字节序列” 之间的映射关系。(ASCII/GBK/UTF8/UTF16 等)
- “Unicode 编码”将这个映射过程拆分为两部分:Codepoint 映射 + 字节转换格式。
- “Codepoint 映射”是指 可打印“字符” 与 uint32 数字 之间的映射关系,这个 uint32 数字 称为 Codepoint。
- “字节转换格式”是指将 Codepoint 转换为 “存储字节序列”的具体转换方法。
- “UTF8”全称是“Unicode Transformation Format - 8 bits”。
- UTF8 这个名称包含两个信息,一是使用 Codepoint 映射,二是定义了转换方法。
“A”和“好”这两个字符在各种编码下的数值表示如下:
| 字符 | ASCII | Unicode 的 Codepoint | UTF8 编码字节 | UTF16 编码 | GBK 的 Codepoint | GBK 编码字节 |
|---|---|---|---|---|---|---|
| A | 65 | 65 | 0x41 | 0x0041 | 65 | 0x41 |
| 好 | 无 | 22909 | 0xE5 0xA5 0xBD | 0x597D | 50106 | 0xBA 0xC3 |
UE4中打印“好”字的UTF8编码和UTF16编码,示例如下:
const char* Utf8Str = u8"好";
for (const char Char : FAnsiStringView(Utf8Str))
{
const uint32 Byte = static_cast<uint32>(static_cast<uint8>(Char));
UE_LOG(LogTemp, Warning, TEXT("char byte: %u"), Byte);
}
const TCHAR* Chinese = TEXT("好");
for (const TCHAR Char : FStringView(Chinese))
{
const uint32 Code = static_cast<uint32>(Char);
UE_LOG(LogTemp, Warning, TEXT("TCHAR 2 byte: %u"), Code);
}
// Output:
// char byte: 229
// char byte: 165
// char byte: 189
// TCHAR 2 byte: 22909
UE4字符串转换逻辑中,Codepoint是一个重要概念,如下截图:
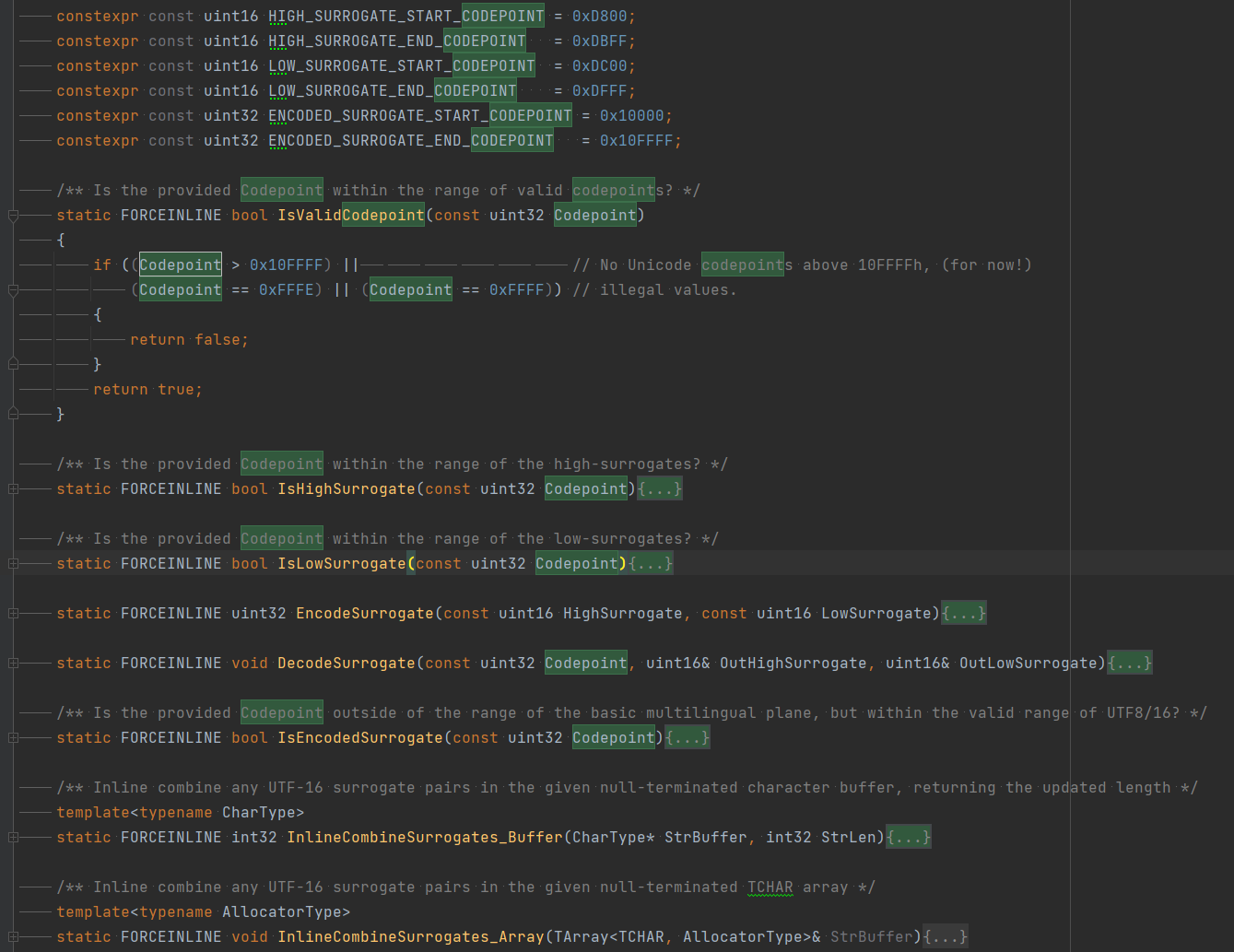
字符类型¶
- “存储字节序列” 共有三种:单字节序列、双字节序列、四字节序列。
- UE 中: ANSICHAR 是 char,WIDECHAR 是 双字节版本,TCHAR 默认定义是 WIDECHAR。
三种字节序列在各个平台对应的数据类型如下:(最后一行为对应的编码格式)
| 平台 | 单字节 | 双字节 | 四字节 |
|---|---|---|---|
| Windows: | char | wchar_t | char32_t |
| Linux: | char | char16_t | wchar_t |
| MacOSX: | char | char16_t | wchar_t |
| 字符编码 | ASCII/UTF8 | UTF16 | UTF32 |
几种数据类型对应的字面量前缀如下:
| 编码 | 类型 | 字面量前缀 | 代码示例 |
|---|---|---|---|
| ASCII | char | 无 | "Hello" |
| UTF8 | char | u8 | u8"World" |
| UTF16 | char16_t | u | u"Nice" |
| UTF32 | char32_t | U | U"Good" |
| UTF16/UTF32 | wchar_t | L | L"Stupid" |
由于双字节版本在不同平台对应不同数据类型,这导致需要不同的字面量前缀,因此UE4需要使用TEXT宏包装一下字符串字面量:
// If we don't have a platform-specific define for the TEXT macro, define it now.
#if !defined(TEXT) && !UE_BUILD_DOCS
#if PLATFORM_TCHAR_IS_CHAR16
#define TEXT_PASTE(x) u ## x
#else
#define TEXT_PASTE(x) L ## x
#endif
#define TEXT(x) TEXT_PASTE(x)
#endif
看 UE 源码注释中说明设计之初是 TCHAR 可以在 ANSICHAR 和 WIDECHAR 之间任意切换,然而实际引擎中某些地方默认 TCHAR 是 2 字节,不再支持切 ANSICHAR,例如:
- TEXT 宏
- ByteSwap、FStringView
- TStringBuilder/TAnsiStringBuilder: 直接不提供 Wide 版本
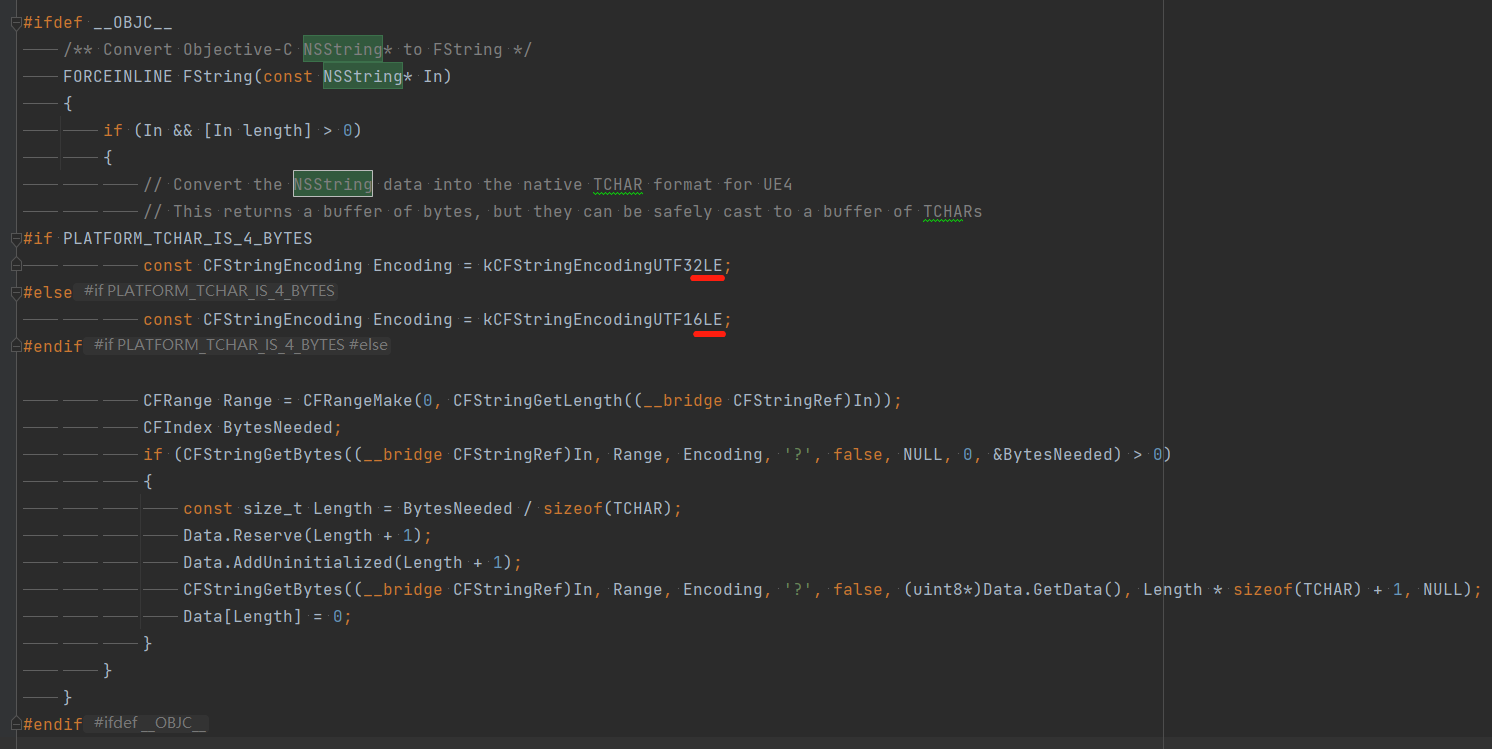
对于双字节和四字节,自然存在一个字节序的问题,UE4默认使用小端模式,这点可以从FString转NSString的代码中看出:
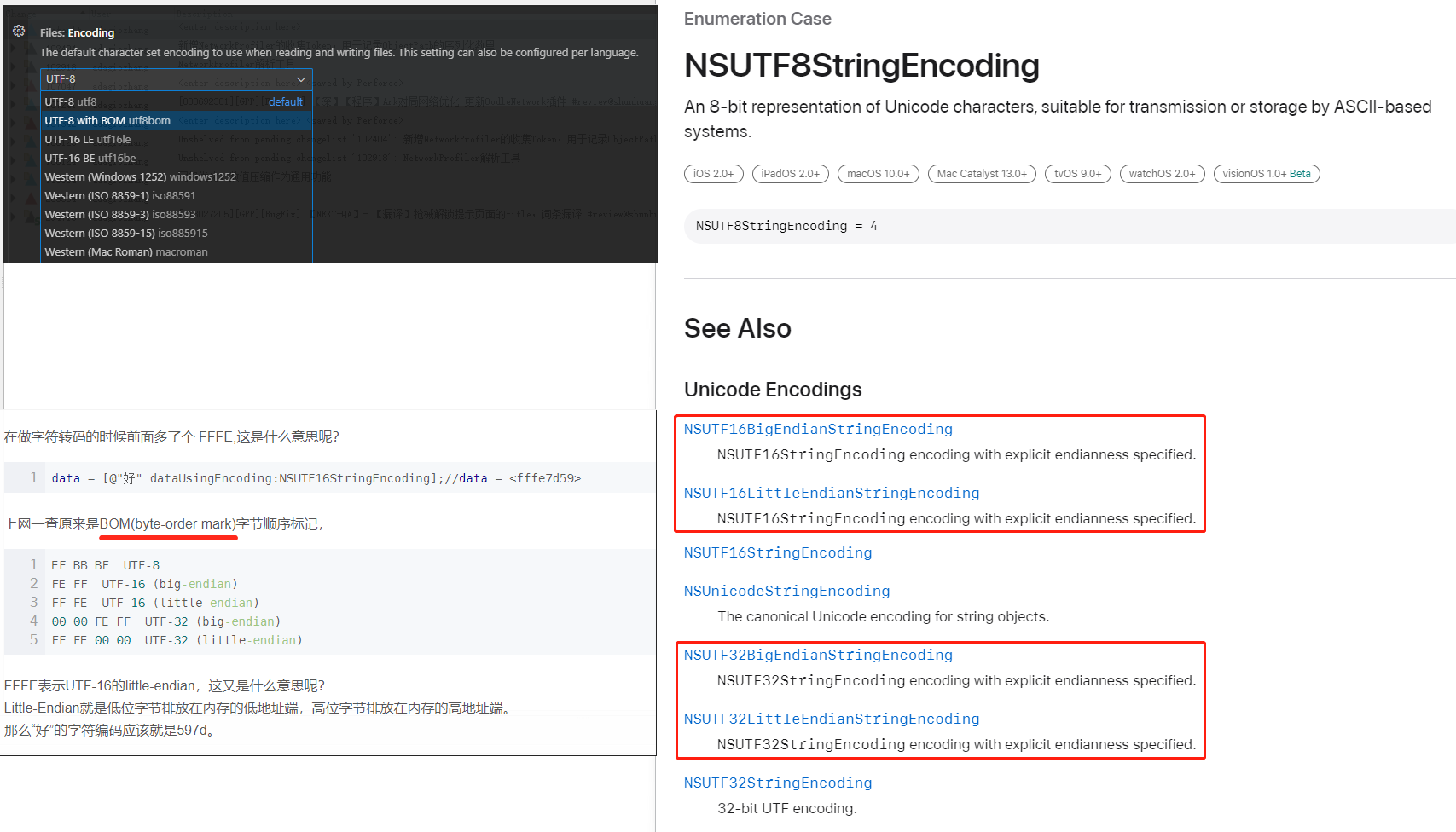
Unicode编码的文件开头可以有一个BOM前缀,这个前缀就是来记录对应编码的大小端信息:
UE 提供的字符串编码转换¶
临时版本:
| 与 TCHAR 互转 | 宏 |
|---|---|
| Ansi | TCHAR_TO_ANSI、ANSI_TO_TCHAR |
| UTF8 | TCHAR_TO_UTF8、UTF8_TO_TCHAR |
| UTF16 | TCHAR_TO_UTF16、UTF16_TO_TCHAR |
| UTF32 | TCHAR_TO_UTF32、UTF32_TO_TCHAR |
默认 TCHAR 数组是 UTF16 格式,因此相关转换只是强制类型转换:
#define TCHAR_TO_UTF32(str) (UTF32CHAR*)(str)
#define UTF32_TO_TCHAR(str) (TCHAR*)(str)
需要持有:找到宏定义,截取前面构造转换对象的一段即可。例如,TCHAR 与 ANSI 互转的持有代码如下:
#define TCHAR_TO_ANSI(str) (ANSICHAR*)StringCast<ANSICHAR>(static_cast<const TCHAR*>(str)).Get()
#define ANSI_TO_TCHAR(str) (TCHAR*)StringCast<TCHAR>(static_cast<const ANSICHAR*>(str)).Get()
// TCHAR_TO_ANSI
auto Caster = StringCast<ANSICHAR>(Str);
const char* Ansi = Caster.Get();
const int32 Len = Caster.Length();
// ANSI_TO_TCHAR
auto Caster = StringCast<TCHAR>(CharStr);
const TCHAR* Str = Caster.Get();
const int32 Len = Caster.Length();
注意:
- 不要强行使用临时版本宏的结果给变量赋值
- 不要用 BytesToString 和 StringToBytes(UE 会莫名其妙的给 Byte 加减 1)
字符串相关工具¶
- FStringView/FAnsiStringView/FWideStringView: 一段字符串的引用。
- TStringBuilder/TAnsiStringBuilder: 避免字符串操作过程创建临时字符串。
- FChar/FCharAnsi/FCharWide: IsUpper、IsAlpha、IsWhitespace 等判断字符类型的函数。
- FCString/FCStringAnsi/FCStringWide: Strcpy、Strcat、Strcmp、Stricmp 等函数,支持是否区分大小写。
- UE::String::BytesToHex/HexToBytes: 形如
TEXT("43AF")的字符串与字节互转,一个字节放两个 16 进制数。 - LexToString/LexFromString: 通用全局模板,理论上支持任意数据结构与 FString 互转。
- FStringFormatter: 通过
FString::Format来使用,类似FText::Format的功能,同样支持 Array 或 Map 的格式化参数。 - ExpressionParser: 通用的表达式解析框架,FStringFormatter、FBasicMathExpressionEvaluator、FUnitConversion、FFrameRateParser 等解析功能都使用这个框架。
一个 Bug¶
FString::FormatStrict的实现中,定义 Token 时 StrictOrderedDefinitions 编码错误。不过貌似在引擎中并没有使用的地方。
函数对象 TFunction&Delegate¶
内存视角长什么样?
TFunction¶
- TFunction 内存分布图
- TUniqueFunction: 不可复制,只能移动的 TFunction,保证只有一个实例
- TFunctionRef: TFunction 的引用,相比 TFunction<>& 更加彻底
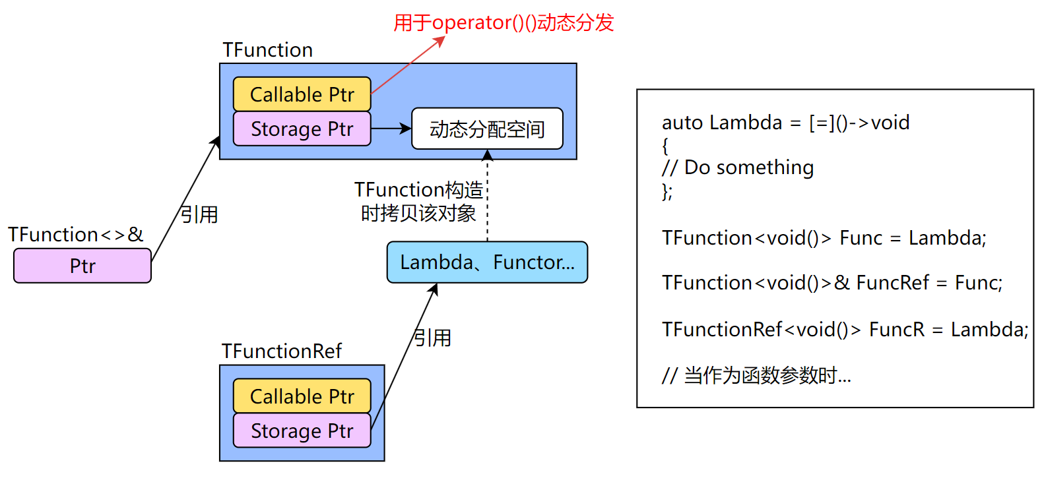
Delegate¶
Delegate 内存分布图:
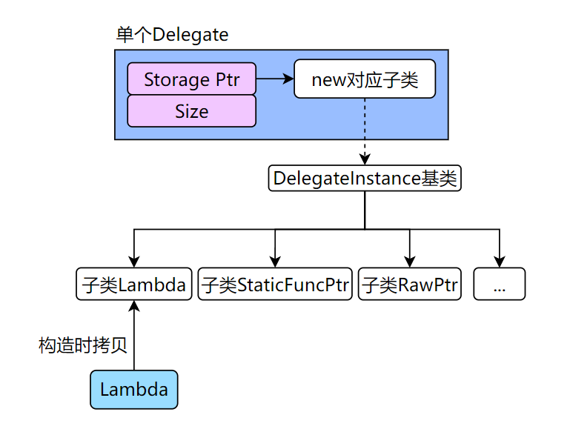
对一个 Delegate 执行 BindLambda、BindSP 等操作时,内部是 new 了一个对应的子类对象。Multicast 版本是元素为 Delegate 的 Tarray。
// Native C++ Only
DECLARE_DELEGATE
DECLARE_DELEGATE_RetVal
DECLARE_MULTICAST_DELEGATE
// UObject Support
DECLARE_DYNAMIC_DELEGATE
DECLARE_DYNAMIC_DELEGATE_RetVal
DECLARE_DYNAMIC_MULTICAST_DELEGATE
DECLARE_EVENT
多线程 TaskGraph & Async¶
有多少异步多线程用法?
四种多线程接口¶
四种接口具体如下:
- ParallelFor/ParallelForWithPreWork
- AsyncTask
- TaskGraph 用法(TaskGraphInterfaces.h 中 FGenericTask 注释)
- TPromise+TFuture
访问临界区考虑加锁或使用无锁数据结构。
四种接口对应的使用案例如下:
class FSumTask
{
int32 Value;
int32 RealResult;
public:
FSumTask(int32 InValue, int32 InRealResult)
: Value(InValue), RealResult(InRealResult)
{
}
~FSumTask()
{
}
FORCEINLINE TStatId GetStatId() const
{
RETURN_QUICK_DECLARE_CYCLE_STAT(FSumTask, STATGROUP_TaskGraphTasks);
}
static ENamedThreads::Type GetDesiredThread()
{
return ENamedThreads::AnyThread;
}
static ESubsequentsMode::Type GetSubsequentsMode()
{
return ESubsequentsMode::FireAndForget;
}
void DoTask(ENamedThreads::Type CurrentThread, const FGraphEventRef& MyCompletionGraphEvent)
{
int32 Total = 0;
for (int32 I = 1; I <= Value; ++I) { Total += I; }
UE_LOG(LogTemp, Warning, TEXT("FSumTask SumResult: %d, RealResult: %d"), Total, RealResult);
// MyCompletionGraphEvent->DontCompleteUntil(TGraphTask<FSomeChildTask>::CreateTask(NULL,CurrentThread).ConstructAndDispatchWhenReady());
}
};
void DoTest()
{
auto Sum = [](int32 StartInclude, int32 EndInclude)->int32
{
int32 Total = 0;
for (int32 I = StartInclude; I <= EndInclude; ++I)
{
Total += I;
}
return Total;
};
constexpr int32 Value = 10'500;
constexpr int32 RealResult = (1 + Value) * Value / 2;
constexpr int32 PerTask = 1'000;
constexpr int32 NumTask = Value / PerTask;
constexpr int32 TheRest = Value % PerTask;
TArray<int32> TaskResult;
TaskResult.AddDefaulted(NumTask);
int32 RestResult = 0;
ParallelForWithPreWork(NumTask, [&](int32 Index)->void
{
const int32 Start = Index * PerTask + 1;
const int32 EndInclude = Index * PerTask + PerTask;
TaskResult[Index] = Sum(Start, EndInclude);
}, [&]()->void
{
const int32 Start = NumTask * PerTask + 1;
RestResult = Sum(Start, Value);
});
int32 Total = RestResult;
for (const int32 Result : TaskResult)
{
Total += Result;
}
UE_LOG(LogTemp, Warning, TEXT("ParallelFor SumResult: %d, RealResult: %d"), Total, RealResult);
AsyncTask(ENamedThreads::AnyThread, [Value, RealResult]()->void
{
int32 Total = 0;
for (int32 I = 1; I <= Value; ++I) { Total += I; }
UE_LOG(LogTemp, Warning, TEXT("AsyncTask SumResult: %d, RealResult: %d"), Total, RealResult);
});
TGraphTask<FSumTask>::CreateTask().ConstructAndDispatchWhenReady(Value, RealResult);
constexpr int32 Middle = Value / 2;
const auto Calculus1 = Async(EAsyncExecution::TaskGraph, [&Sum, Middle]()->int32
{
return Sum(1, Middle);
});
const auto Calculus2 = Async(EAsyncExecution::TaskGraph, [&Sum, Middle, Value]()->int32
{
return Sum(Middle + 1, Value);
});
const int32 CalculusTotal = Calculus1.Get() + Calculus2.Get();
UE_LOG(LogTemp, Warning, TEXT("Async Future SumResult: %d, RealResult: %d"), CalculusTotal, RealResult);
}
几种用法的选择¶
调用端视角为同步操作:
- 单个或多个完全不同的任务:使用 TPromise+TFuture( Async 方法)
- 多个相似的任务:抽取相同计算使用 ParallelFor,额外计算使用 WithPreWork
调用端视角为异步操作:
- 单一任务或多个无依赖任务:使用 AsyncTask
- 多个相互依赖的任务:直接自定义 FGenericTask,实现精细化控制
宏展开规则 Macros¶
宏展开真的只是字符串替换吗?
两种宏展开方式¶
如下宏定义与使用的代码中,编译预处理应该走哪种展开方式:
#define FEATURE_A(x, y) ((x)+(y))
#define MODIFY_B(x) ((x) + 1)
#define MODIFY_C(x) ((x) + 2)
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55));
// 第一种展开方式
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55));
auto Result = (MODIFY_B(43) + MODIFY_C(55));
auto Result = (((43) + 1) + ((55) + 2));
// 第二种展开方式
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55));
auto Result = FEATURE_A(((43) + 1), ((55) + 2));
auto Result = (((43) + 1) + ((55) + 2));
// 如果 FEATURE_A 是如下定义呢?
#define FEATURE_A(x, y) #x
#define FEATURE_A(x, y) Hello##x##y##World
#define FEATURE_A(x, ...) LOG(x, ##__VA_ARGS__)
// 第一种展开
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55));
auto Result = "MODIFY_B(43), MODIFY_C(55)";
// 第二种展开
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55));
auto Result = FEATURE_A(((43) + 1), ((55) + 2));
auto Result = "((43) + 1), ((55) + 2)";
C++宏展规则¶
从外层到内层,每一步展开之后,再从整体的角度执行整个流程。规则如下:
- 宏实现带#或##,优先展开
- 展开宏参数中附带的宏
- 宏实现不带#或##,最后展开
一个宏调用包含了宏本身和宏实参,展开顺序确定了宏本身和宏实参的展开先后顺序。如果宏本身实现带有#或##,优先展开;反之,宏本身实现无#或##,宏实参优先展开。
宏展开流程图:

// 宏实现带有#或##,仍需要实参优先展开,则需要套一层:
#define FEATURE_A(x, y) FEATURE_A_INNER(x, y)
#define FEATURE_A_INNER(x, y) #x
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55)); // 此时展开顺序如下:宏实参先展开
auto Result = FEATURE_A(MODIFY_B(43), MODIFY_C(55));
auto Result = FEATURE_A(((43) + 1), ((55) + 2));
auto Result = "((43) + 1), ((55) + 2)";
UE 中有大量嵌套一层的宏定义,目的就是让实参优先展开。
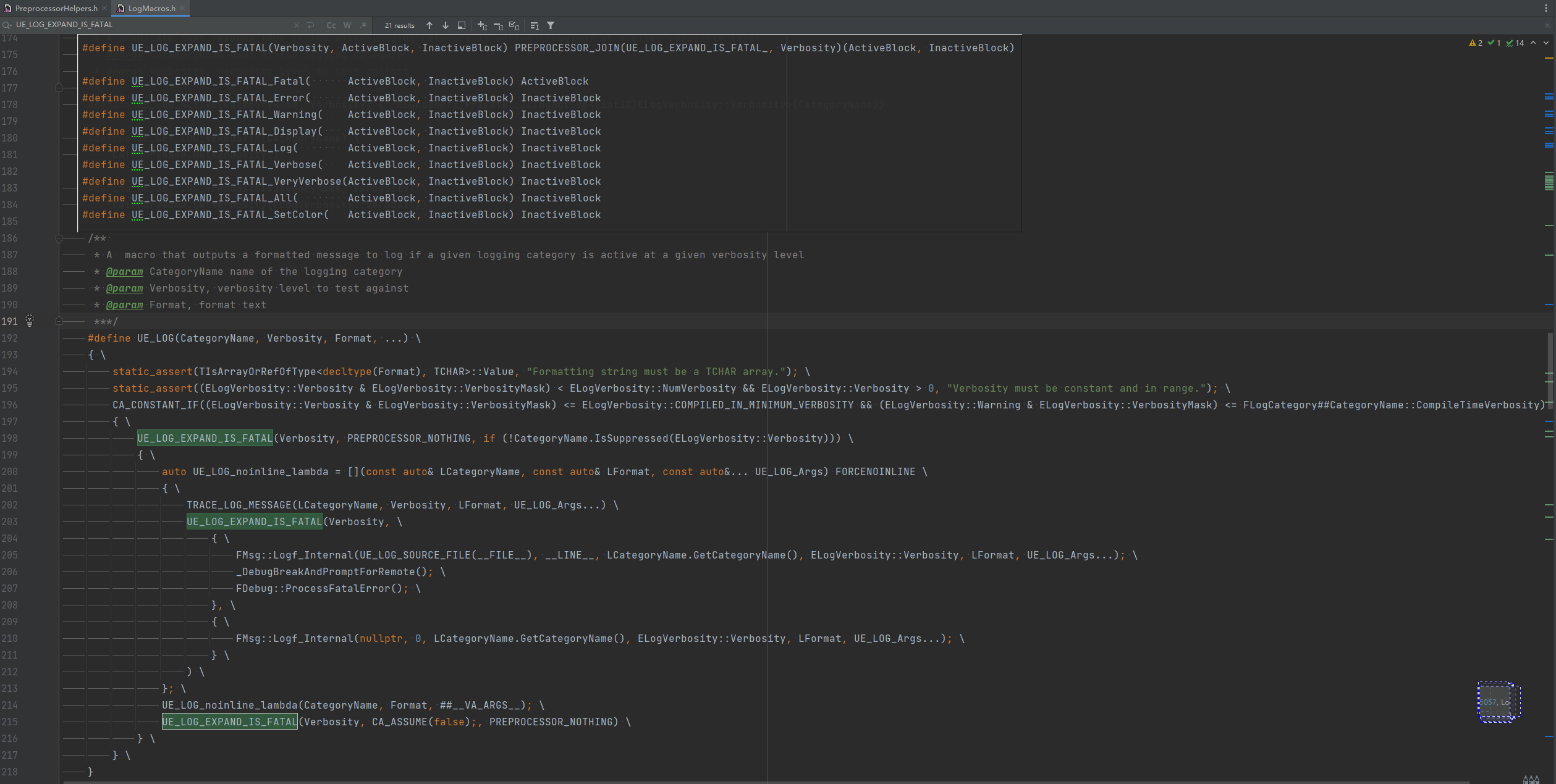
举例¶
// Concatenates two preprocessor tokens, performing macro expansion on them first
#define PREPROCESSOR_JOIN(x, y) PREPROCESSOR_JOIN_INNER(x, y)
#define PREPROCESSOR_JOIN_INNER(x, y) x##y
// Expands to the second argument or the third argument if the first argument is 1 or 0 respectively
#define PREPROCESSOR_IF(cond, x, y) PREPROCESSOR_JOIN(PREPROCESSOR_IF_INNER_, cond)(x, y)
#define PREPROCESSOR_IF_INNER_1(x, y) x
#define PREPROCESSOR_IF_INNER_0(x, y) y
#define TEXT(x) PREPROCESSOR_IF(PLATFORM_TCHAR_IS_CHAR16, u##x, L##x)
const TCHAR* Str = TEXT("HelloWorld!");
// Windows平台展开过程如下:
const TCHAR* Str = TEXT("HelloWorld!");
const wchar_t* Str = PREPROCESSOR_IF(PLATFORM_TCHAR_IS_CHAR16, u"HelloWorld!", L"HelloWorld!");
const wchar_t* Str = PREPROCESSOR_IF(0, u"HelloWorld!", L"HelloWorld!");
const wchar_t* Str = PREPROCESSOR_JOIN(PREPROCESSOR_IF_INNER_, 0)(u"HelloWorld!", L"HelloWorld!");
const wchar_t* Str = PREPROCESSOR_IF_INNER_0(u"HelloWorld!", L"HelloWorld!");
const wchar_t* Str = L"HelloWorld!";
// 这种情况还能正确展开吗?TEXT宏需要如何调整?
#define NOTHING(x) x
const TCHAR* Str = TEXT(NOTHING("HelloWorld!"));
#用于将标识符变成字符串,##用于连接标识符和变参,参考:https://www.zhaixue.cc/c-arm/c-arm-macro.html。
UE 反射实现函数重载¶
- virtual 函数仅父类声明 UFUNCTION 标签:仅允许 C++重写,蓝图和 C++都能调用。
- BlueprintImplementableEvent:仅允许蓝图重写,蓝图和 C++都能调用。
- BlueprintNativeEvent:蓝图和 C++都能重写,子类覆盖父类,蓝图和 C++都能调用。
- 蓝图调用 C++的要求是 C++必须提供一个固定函数原型的 exec 函数。
- C++调用蓝图则是通过 FindFunction+ProcessEvent 来实现。
- UFUNCTION 默认标签提供了 exec 函数,蓝图调 C++。
- ImplementableEvent 则提供了 FindFunction+ProcessEvent,C++调用蓝图。
- NativeEvent 要互调,所以两者都有,声明的函数提供 FindFunction+ProcessEvent 支持 C++调用蓝图,带_Implementation 后缀的函数则搭配 exec 函数实现蓝图调 C++。
更多 More¶
ON_SCOPE_EXIT宏的使用(针对中途 return、throw 异常)类似的可以定义一些结构体来做 Scoped 功能,例如TGuardValue。LIKELY和UNLIKELY,参考:https://www.zhaixue.cc/c-arm/c-arm-builtin.html- 数据预取:UE 提供了
FPlatformMisc::Prefetch和FPlatformMisc::PrefetchBlock用于支持手动触发数据预取,减少读取延迟,从而提高性能。(https://www.cnblogs.com/dongzhiquan/p/3694858.html) - TransformCalculus.h 的注释详细讲解了坐标空间的变换规则
- 普通继承自 UObject 的蓝图类中需要重写一个不依赖
UObject::GetWorld的GetWorld,才能调用静态的带有(meta=(WorldContext="WorldContextObject"))标记的函数。(GetWorld自行实现一般是将Outer强转为某个已知的 Actor 类型,使用该 Actor 的GetWorld,否则返回nullptr。避免这个问题也可以给类meta加ShowWorldContextPin标签或给函数meta加CallableWithoutWorldContext标签) - 使用
PRAGMA_DISABLE_OPTIMIZATION和PRAGMA_ENABLE_OPTIMIZATION可以关闭一部分代码的编译优化
| 断言宏 | 关闭检查后表达式是否依旧执行? | 触发断言是否继续执行? | 是否能在if条件中使用? |
|---|---|---|---|
| check | 否,关闭检查后宏展开为空 | 否,直接 Crash | 否,无返回值 |
| verify | 是 | 否,直接 Crash | 否,无返回值 |
| ensure | 是 | 是 | 是,返回值为表达式计算结果 |